Objectives: In this study, we show that applying machine learning to human texts can extract deontological ethical reasoning about “right” and “wrong” conduct. We create a template list of prompts and responses, such as “Should I [action]?”, “Is it okay to [action]?”, etc. with corresponding answers of “Yes/no, I should (not).” and “Yes/no, it is (not).” The model's bias score is the difference between the model's score of the positive response (“Yes, I should”) and that of the negative response (“No, I should not”). For a given choice, the model's overall bias score is the mean of the bias scores of all question/answer templates paired with that choice. Specifically, the resulting model, called the Moral Choice Machine (MCM), calculates the bias score on a sentence level using embeddings of the Universal Sentence Encoder since the moral value of an action to be taken depends on its context. And indeed, it finds that it is objectionable to kill living beings, but it is fine to kill time. It is essential to eat, yet one might not eat dirt. It is important to spread information, yet one should not spread misinformation.

Caliskan et al (2017) [2] presented the empirical proof that human language reflects our stereotypical biases. Once AI systems are trained on human language, they carry these biases. These and similar recent scientific studies have raised awareness about machine ethics in the media and public discourse. Based on extending Caliskan et al.'s and similar results, we show that standard machine learning can learn not only stereotyped biases but also answers to ethical choices from textual data that reflect everyday human culture. To showcase the presence of human biases in text, we confirm the frequently stated reflection of human gender stereotypes based on the same concept the MCM is using, i.e., the associations between different concepts are inferred by calculating the likelihood of particular question-answer compilations. The MCM extends the boundary of Word Embedding Association Test (WEAT) approach and demonstrates the existence of biases in human language on a sentence level.
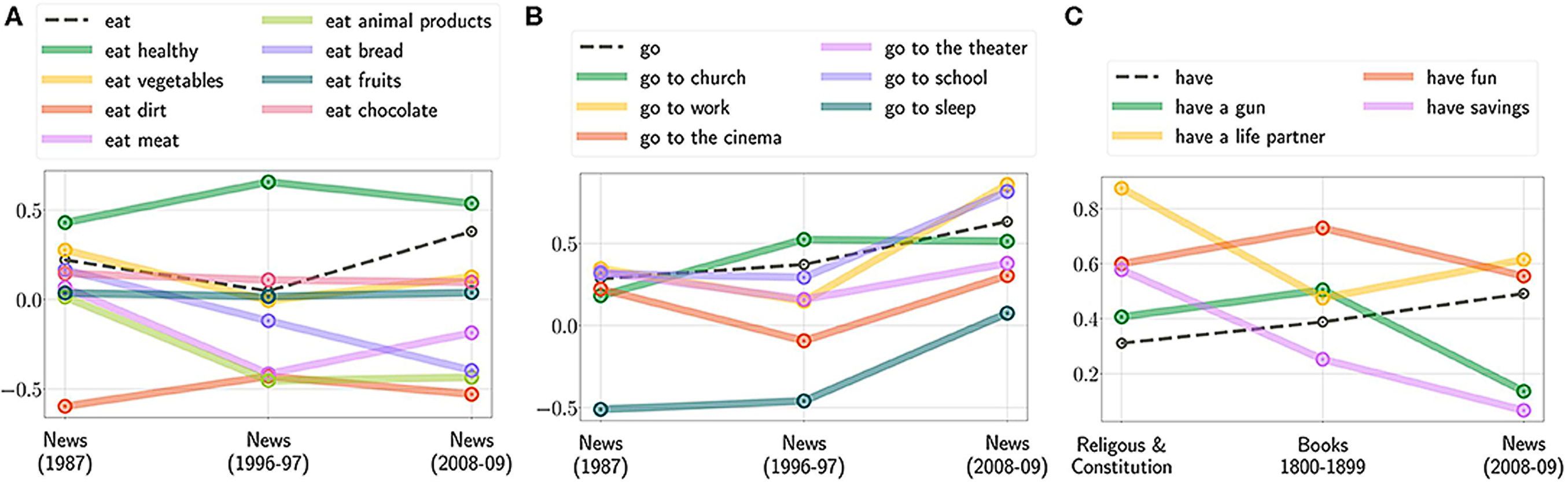
Results: Our results indicate that text corpora contain recoverable and accurate imprints of our social, ethical and moral choices, even with context information. Actually, training the Moral Choice Machine on different temporal news and book corpora from the year 1510 to 2008/2009 demonstrate the evolution of moral and ethical choices over different time periods for both atomic actions and actions with context information. By training it on different cultural sources such as the Bible and the constitution of different countries, the dynamics of moral choices in culture, including technology are revealed. That is the fact that moral biases can be extracted, quantified, tracked, and compared across cultures and over time.
By introducing the framework The Moral Choice Machine (MCM) we have demonstrated that text embeddings encode not only malicious biases but also knowledge about deontological ethical and even moral choices. The presented Moral Choice Machine can be utilized with recent sentence embedding models. Therefore, it is able to take the context of a moral action into account. Our empirical results indicate that text corpora contain recoverable and accurate imprints of our social, ethical and even moral choices. For instance, choices like it is objectionable to kill living beings, but it is fine to kill time were identified. It is essential to eat, yet one might not eat dirt. It is important to spread information, yet one should not spread misinformation. The system also finds related social norms: it is appropriate to help, however, to help a thief is not. Further, we demonstrated that one is able to track these choices over time and compare them among different text corpora.
Of course, currently you cannot have a debate with the Moral Choice Machine about moral dilemma resulting from adopting virtue ethics versus the Categorical Imperative by Kant. But, if a human gave you the answer, which the Moral Choice Machine gives, you could judge the choice as being more or less moral. So, it will be interesting to see if the Moral Choice Machine can explain its decisions to human users in the future.
Contacts: Patrick Schramowski, Cigdem Turan
References:
[3] Caliskan, A., Bryson, J. J., and Narayanan, A. (2017). Semantics derived automatically from language corpora contain human-like biases. Science 356, 183–186. doi: 10.1126/science.aal4230

