
Learning to segment human sequential behavior to detect the intention for interaction
Author: Lisa Scherf
Supervisors: Prof. Constantin Rothkopf, PhD., Susanne Trick
Submission: January 2021
Abstract:
Humans subconsciously recognize intentions among each other and react accordingly. They can easily decide if and when another person intends to engage in an interaction, but for assistive robots this is still a pressing task.
In order to achieve a more intuitive interaction between humans and robots, this study investigates how humans signal an intention-for-interaction and how these signals can be detected. A block building experiment is used to build a multimodal dataset of human-human interactions covering a variety of different interactions and the preceding intentions-for-interactions. The general task was to assemble a tower from building blocks following step-by-step instructions. The design of the experiment triggers the participants to initiate different kinds of interactions with the investigator. The malfunctioning of a pen or a subtask requiring help from the investigator are examples for situations leading to an intention-for-interaction.
Two supervised classifiers – a logistic regression model and a long short-term memory network – are trained on this manually labeled dataset and achieve good performance using a combination of orientation, eye-gaze, and acoustic features to predict the probability of an intention-for-interaction.
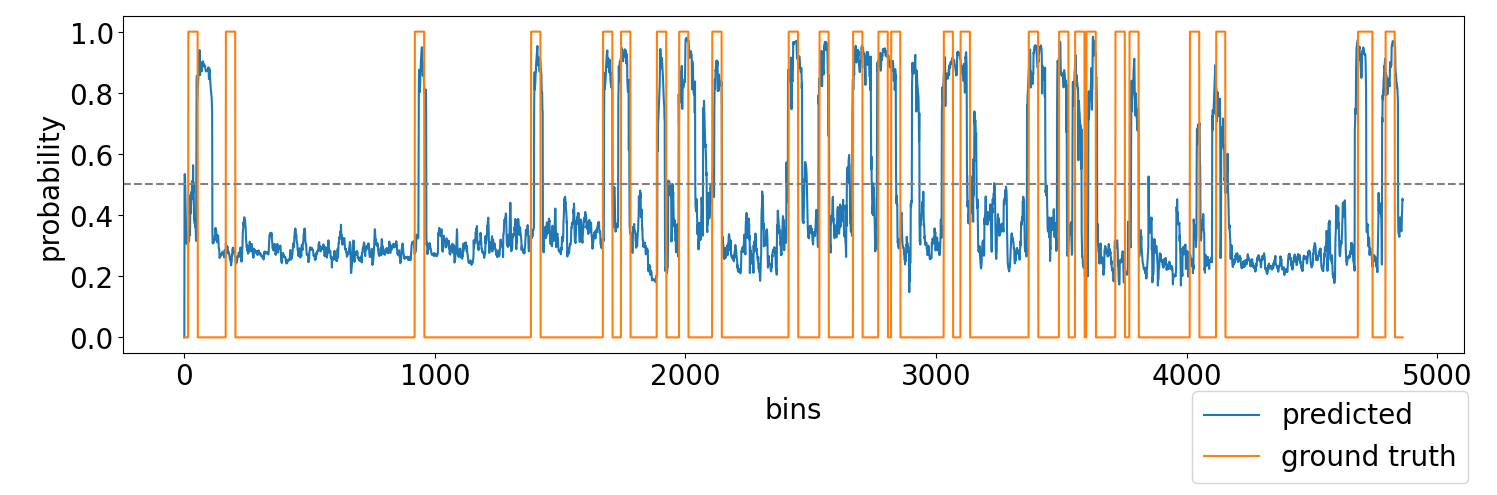
Experimental validation shows that a multimodal feature set gives better precision and recall than using only one feature. The results indicate the existence of behavioral patterns for an intention-for-interaction across different people and situational contexts.

