Bessere Interaktion mit Künstlicher Intelligenz
Veröffentlichung in „Nature Machine Intelligence“
10.03.2023
Ein Team von Forschern der TU Darmstadt, hessian.AI und des Deutschen Forschungszentrums für Künstliche Intelligenz hat eine Methode vorgestellt, die das Geben menschlichen Feedbacks an eine lernende Software erheblich vereinfacht. Die Arbeit erscheint in der aktuellen Ausgabe von „Nature Machine Intelligence“.

Alle Welt staunt über ChatGPT: Die Sprach-KI beantwortet Fragen, schreibt Referate und spuckt sogar Gedichte aus. Zum Erfolg der lernfähigen Software trägt ihr menschlicher Schreibstil bei. Für Felix Friedrich von der Technischen Universität Darmstadt ist ChatGPT ein Beispiel dafür, wie wichtig die Interaktion zwischen Mensch und Maschine ist. Denn die Eloquenz der Software stammt nicht nur von den Millionen an digitalen Texten, mit denen sie sich selbst trainiert hat, sondern auch von einer Verfeinerung dieses Trainings im Dialog mit dem Menschen.
Viele KI-Algorithmen profitieren bereits von Feedback durch den Menschen, wie Darmstädter Forscher um Professor Kristian Kersting vom Fachbereich Informatik in den letzten Jahren gezeigt haben. Jedoch sei das Potenzial bei weitem noch nicht ausgeschöpft, ist Felix Friedrich überzeugt, der bei Kersting promoviert. Nun stellt der Informatiker zusammen mit Kollegen eine Methode vor, die das Geben menschlichen Feedbacks erheblich vereinfacht. Die Arbeit erscheint in der aktuellen Ausgabe des renommierten Fachmagazins „Nature Machine Intelligence“.
Welche Signale tragen zu einer Entscheidung der KI bei?
Um mit Maschinen zu kommunizieren, muss man sie verstehen. Doch das ist bei der aktuell meist verwendeten Form von KI, dem so genannten Deep-Learning, schwierig. Deep-Learning ist inspiriert durch neuronale Verbindungen in biologischen Gehirnen. Große Deep-Learning-Netze besitzen Milliarden Verbindungen zwischen virtuellen Neuronen. Es ist schwer nachvollziehbar, welche Signale zu einer Entscheidung der KI beitragen und welche nicht, wie die Software also zu ihrem Ergebnis kommt. Sie ähnelt einer Black Box.
„Oft fragt man auch nicht danach, solange die KI funktioniert“, sagt Friedrich. Dadurch übersieht man aber leicht, wenn die KI so genannte „Abkürzungen“ nimmt, die zu Fehlern führen können. Was sind solche Abkürzungen? Deep-Learning wird oft eingesetzt, um auf Bildern bestimmte Objekte zu erkennen, beispielsweise: Eisbären. Zum Training setzt man ihr sehr viele Bilder von Eisbären vor, wodurch sie anhand der Gemeinsamkeiten lernen soll, was einen Eisbären ausmacht. Nun kann es sein, dass die KI es sich einfach macht. Wenn bei den Trainingsbildern immer Schnee im Hintergrund war, dann nimmt sie diesen Schnee im Hintergrund als Kennzeichen für ein Eisbärbild, statt den Eisbären selbst. Erscheint nun ein Braunbär vor verschneiter Landschaft, erkennt die KI diesen fälschlich als Eisbären.
Mithilfe einer Methode namens Explainable AI lassen sich solche Fehler aufspüren. Dabei zeigt der Deep-Learning-Algorithmus, welche Muster er für seine Entscheidung verwendet hat. Wenn es die falschen waren, kann ein Mensch dies an die KI zurückmelden, etwa indem er die richtigen Muster zeigt (zum Beispiel die Umrisse des Bären) oder die falschen als falsch markiert. Dieses Feedback-Verfahren bezeichnen die Forscher als Explanatory Interactive Learning (XIL).
Analyse mehrerer XIL-Verfahren
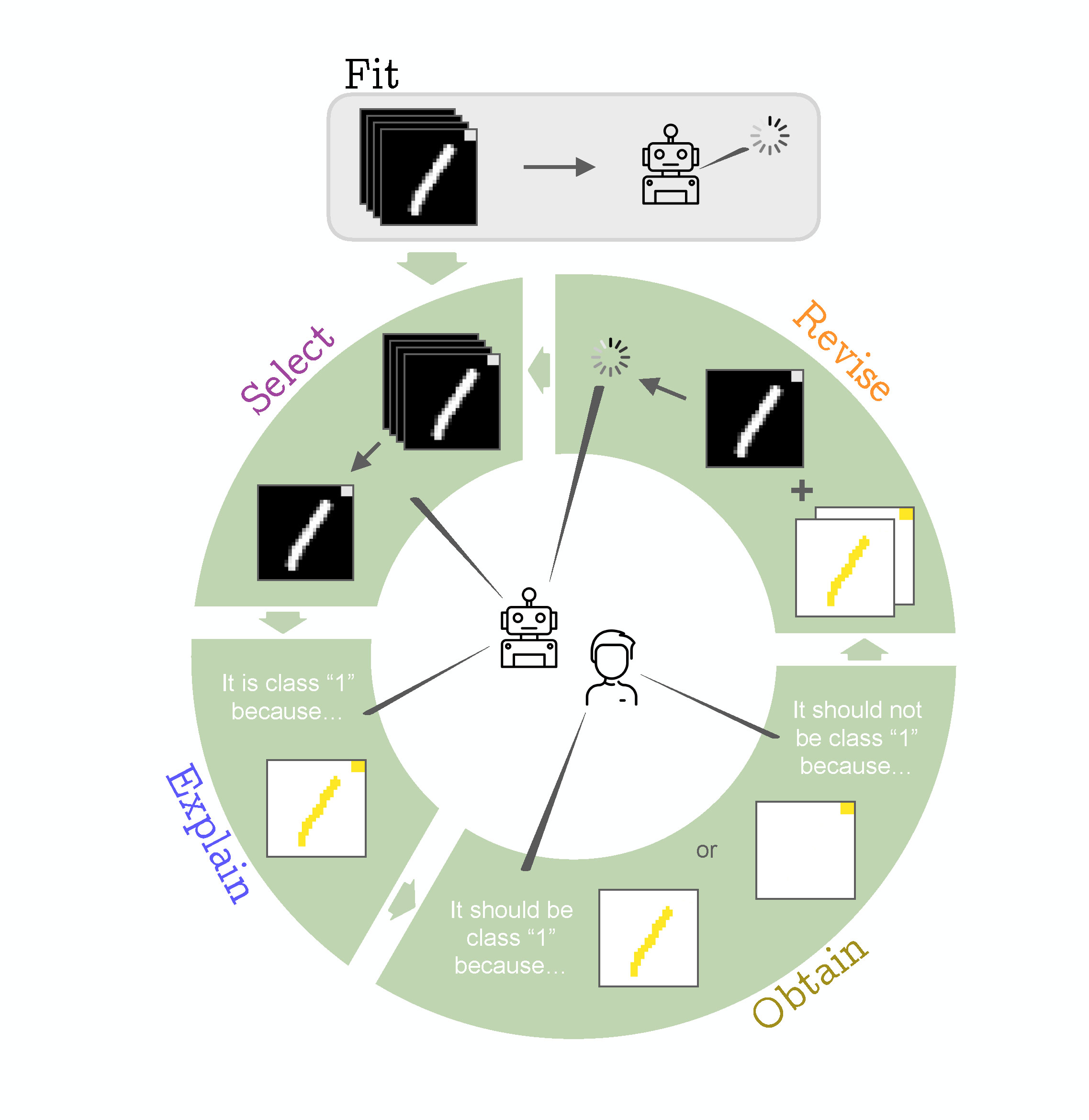
Die Darmstädter Forscher haben nun mehrere existierende XIL-Verfahren untersucht. „Das hatte noch nie jemand systematisch getan“, sagt Felix Friedrich. Akribisch analysierten die Forscher, wie die Interaktion mit dem Computer bei den jeweiligen Methoden abläuft und wo Effizienzgewinne möglich sind. Sie unterschieden, welche Komponenten einer Erklärung wichtig sind und welche nicht. „Es stellte sich heraus, dass es nicht nötig ist, tausende von Markierungen an die Maschine rückzumelden, sondern dass oft eine Handvoll Interaktionen reichen“, sagt Friedrich. Oft genüge es, der KI zu sagen, was nicht zum Objekt gehört, statt zu definieren, was dazugehört.
Konkret haben die Forscher einer KI die Aufgabe gegeben, eine handgeschriebene „1“ zu erkennen. In der Ecke jedes Trainingsbildes war aber auch ein kleines Quadrat. Wenn der Algorithmus dies fälschlicherweise als relevantes Merkmal für die „1“ nimmt, reicht es, das Quadrat als nicht zum Objekt gehörig zu markieren. „Das ist viel effektiver, denn generell ist schwierig zu definieren, was zum Beispiel einen Eisvogel auszeichnet“, erklärt Friedrich.
Die Darmstädter Forscher haben aus den untersuchten XIL-Verfahren eine Strategie („Typology“) destilliert, mit der sich das beschriebene Abkürzungs-Verhalten effizient beheben lässt.
Folgeprojekt bereits gestartet
Felix Friedrich und seine Kollegen arbeiten schon am nächsten Projekt, das die Interaktion zwischen Mensch und Maschine verbessern soll. Diesmal geht es um Text-zu-Bildgeneratoren, die oft einen „Bias“ haben. Auf die Anweisung, einen „Firefighter“ (das geschlechtsneutrale englische Wort für „Feuerwehrmann“) darzustellen, erzeugen sie meist Bilder von weißen Männern mit Feuerwehrhelm, was daran liegt, dass in den Trainingsdaten Bilder von männlichen, weißen Feuerwehrleuten dominieren. Durch menschliche Interaktion wollen die Darmstädter die Trainingsdaten für solche Bildgeneratoren diverser machen, durch Filterung, aber auch durch Hinzufügen von Bildern, etwa von farbigen Feuerwehrleuten. Felix Friedrich kommt damit seinem Ziel einer „Human-guided machine ethics“ näher.
Die Autoren der Veröffentlichung forschen an der Technischen Universität Darmstadt, am Hessischen Zentrum für Künstliche Intelligenz hessian.AI und am Deutschen Forschungszentrum für Künstliche Intelligenz (DFKI). Die Forschung ist Teil des Clusterprojekts „3AI – The Third Wave of Artificial Intelligence“.
Die Veröffentlichung:
Christian Meier/sip